
Teneo Linguistic Modeling Language
Teneo offers support to a wide range of languages, meaning developers can create powerful bots in any one of those languages. Because of the significant variation across different languages, Teneo offers developers an approach called Teneo Linguistic Modeling Language. Teneo Linguistic Modeling Language denotes several aspects in the solution design process that are used to define functionality based on linguistic methods, as opposed to solely using machine learning. Teneo Linguistic Modeling Language, therefore allows developers to create a linguistically perfect solution that takes into account all of the quirks and features of a specific language.
On this page, we will describe in-depth what Teneo Linguistic Modeling Language (referred to as TLML on this page) is, how it works, and how it can benefit a solution.
Language Capabilities
One of Teneo's biggest strengths is in the field of Natural Language Understanding (NLU), as a very wide range of different languages — no matter the complexity — can be fully supported using Match Requirements.
Classes
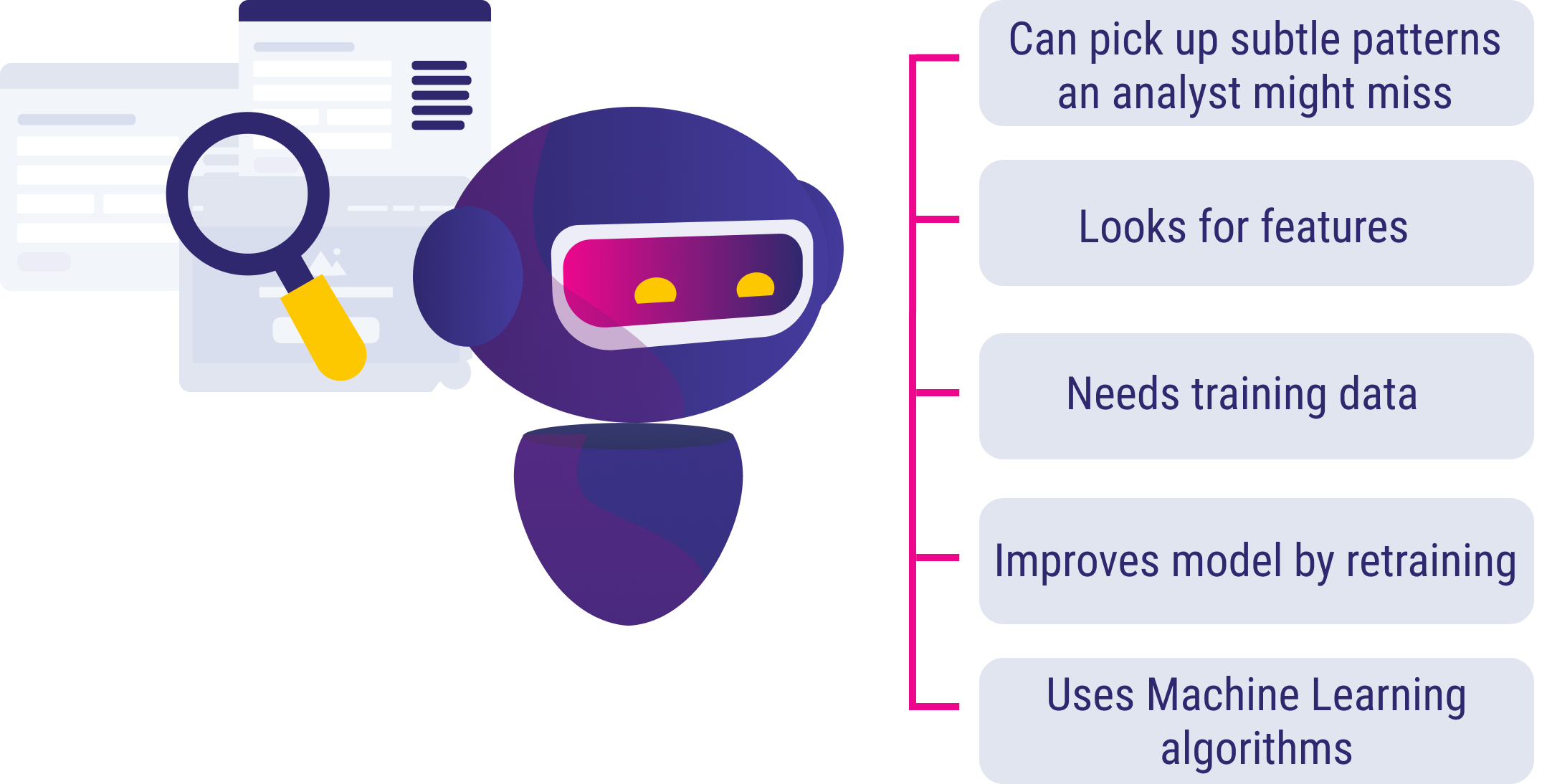
The most general approach in this field is to use machine-learned classes to build your flow. These classes have their training examples on which the model is based. When using a classifier, for example, you do not need to understand the exact characteristics that define what an input is about. You can focus on collecting example inputs for the subjects you want to cover and, once you have trained a model using that data, you simply let the model do its magic. That makes it relatively easy to train a system to understand natural language without the need for linguistic skills or resources.
To get more insight into the exact workings of machine-learned classes, developers can also choose to use their native intent classifier or connect a different one to the solution. One especially powerful option is Conversational Language Understanding and Teneo, which allows you to combine the NLU-power of Conversational Language Understanding (CLU) with the conversational power of Teneo. See Conversational Language Understanding and Teneo to get started with it.
Teneo Linguistic Modeling Language
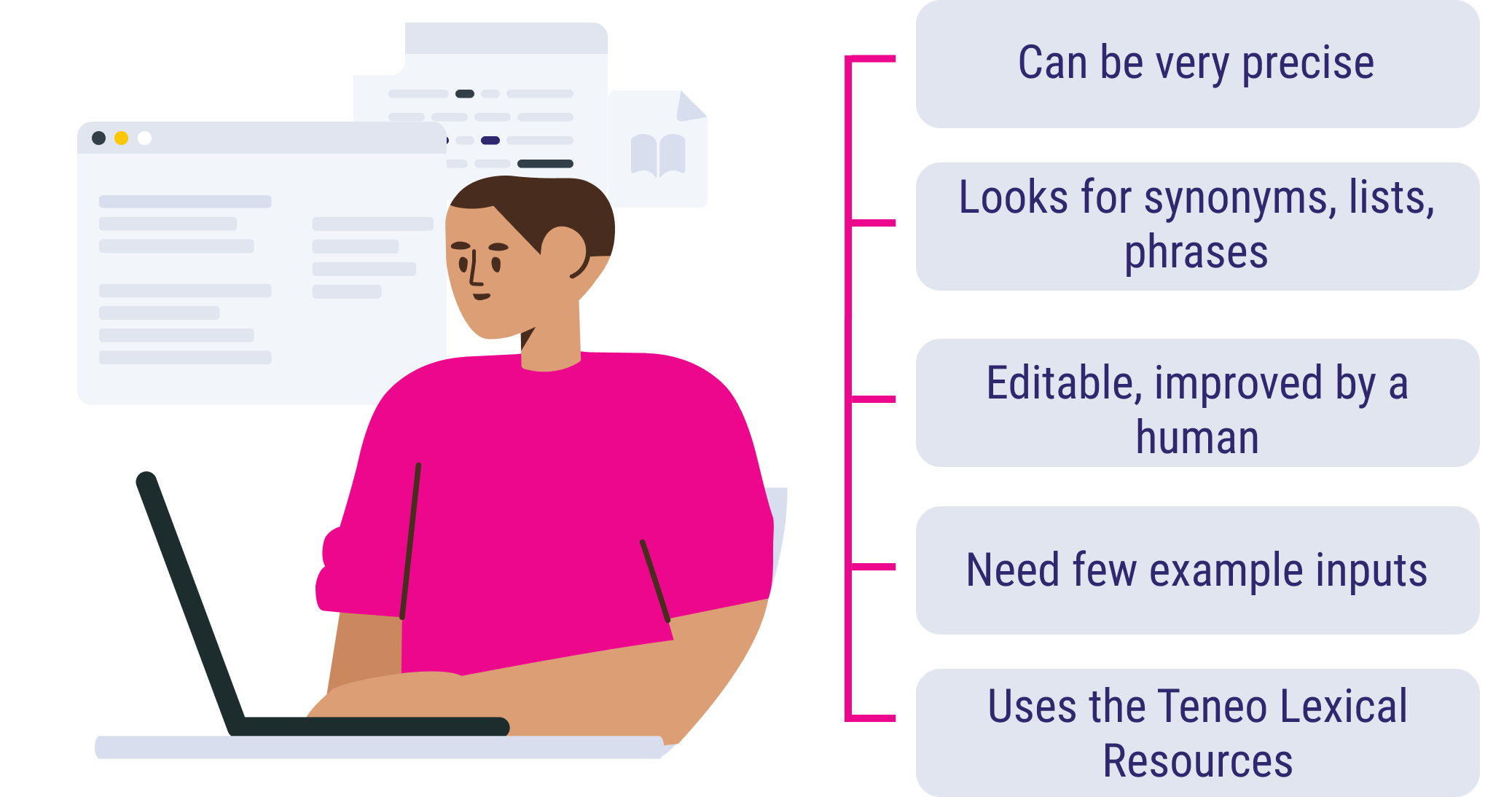
Teneo's unique and proprietary linguistic syntax, Teneo Linguistic Modeling Language (TLML), is one of many features that make Teneo stand out. The option to combine and build linguistic syntax conditions gives the user an opportunity to create a linguistically perfect solution. It is possible to decide on things like what order certain words should be in and if a word or sentence should be written in a specific way.
TLML gives users the option to create their own language objects to cover synonyms, phrases, and entities.
It’s also possible to create your own annotations to only cover certain versions of words, where one common use case in English is to differentiate between singular and plural word forms (e.g. ‘ticket’ and ‘tickets’) using Part-of-Speech tags or detecting e-mail addresses using Named Entity Recognition annotations.
Combining both approaches
Combining both approaches, also known as the 'Hybrid Approach' allows Teneo’s modular approach to use the most suitable machine learning technologies, providing Teneo Learn out of the box but also allowing easy use of external technologies like CLU. This can be seen in our Conversational Language Understanding and Teneo approach.
Teneo has a unique, bespoke, and proprietary syntax that has been designed and field-proven over the years to suit specific Conversational AI needs. Teneo Linguistic Modelling Language is crafted precisely to cater to varied and unexpected input. It is able to capture the only relevant bits of the user input, as well as extract information that can be used later, either in responses or for conversation logic. This approach is designed to be much more efficient than other non-bespoke syntax, and it allows you to use the best technology combination to fit your language, business, or use case requirements.
The 'Hybrid Approach' use a combination of Classes and TLML (linguistic syntax rules) to leverage the best aspects of both machine-learning and linguistic rules; these flows allow for the precision of the linguistic rules to be combined the flexibility of machine learning. Hence giving the developer the chance to both target a large scale of sentence and still be very precise. One practical example of combining both (Classes and Teneo Linguistic Modelling Language) for a hybrid approach can be found here.
Benefits of Teneo Linguistic Modeling Language
Teneo Linguistic Modeling Language (TLML) offers many benefits to developers and solutions. As a developer, you get to create your own TLML, giving you full control over what to focus on in an easy-to-maintain project designed to handle varied and unexpected input. Unlike approaches relying on machine-learned classes, you do not need large amounts of data to put together an efficient and accurate bot using the TLML method.
For certain languages, TLML will be especially beneficial. For example, agglutinative languages tend to perform better with TLML as compared to machine learning. These languages' morphology uses agglutination, meaning the same morpheme may be used in many different words with completely different meanings by use of various affixes; for example, in Indonesian, which is an agglutinative language, the words for "student" and "teacher" consist of the same root word and differ only in affixes used. While a machine learning algorithm would likely fail to correctly differentiate between these two words, the linguistic approach of TLML would make it easy to ensure such cases are handled correctly.
Using TLML will make a good solution turn great, regardless of the language used, many projects may contain all kinds of use cases that are very specific to that particular project. In this case, too, TLML can be very beneficial, as the developer can ensure these use cases are covered.
Conditions
Teneo Linguistic Modeling Language (TLML) are being used in Syntax Conditions which allows developers in Teneo to define their own language rules according to their projects' requirements, rather than having to rely solely on machine learning. In practice, this is done using Teneo's Natural Language Understanding (NLU) capabilities by defining conditions within flows to deal with user input.
For an example of how NLU in conditions can be used to improve TLML, consider the following image. In this condition, the developer has typed the plain text "can i bring", and from this Teneo is able to suggest several different language objects or other annotations that the developer can then use within the condition. These language objects are by themselves covering multiple versions of this same sentence, which eases the work that needs to be done collecting traning data for the intent:
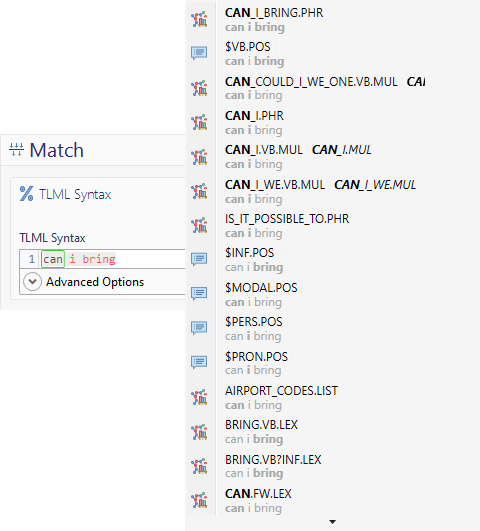
- See Libraries for more information on this topic.
Teneo Linguistic Modeling Language has its own syntax to write conditions for together with the use of Operators. This allows different options of sentences to appear, for example, if the user wants words to appear in a specific order.
The following are a few of the operators available in Teneo.
OR ( / )
When conditions are combined with the OR-operator (/), at least one of them needs to match the input.
| Condition | Matched User Input | Unmatched User Input |
|---|---|---|
| dog / cat / hamster / parakeet / goldfish | I have a dog | I don't like cats or dogs |
AND ( & )
Conditions that are combined with the AND-operator (&) must all match the input. The AND-operator does not require the words in the input to appear in a certain order.
| Condition | Matched User Input | Unmatched User Input |
|---|---|---|
| I & love & you | I love you | everyone loves you |
FOLLOWED BY ( + )
Conditions that are combined with the FOLLOWED BY-operator (+) must all match the input, in the order stated. The operator is a good choice for word combinations whose sense would shift if the word order were rearranged.
| Condition | Matched User Input | Unmatched User Input |
|---|---|---|
| John + loves + Anna | John really loves Anna | Anna loves John |
NOT (!)
The NOT-operator (!) takes only one condition, and states that whatever is specified in that condition must not match the user input.
| Condition | Matched User Input | Unmatched User Input |
|---|---|---|
| !cat | I have a dog | I don't have a cat |
Conditions can be coded manually, or Teneo Studio can automatically generate a condition with the 'Draft' function. This drafted condition is based on the positive testing examples for that node.
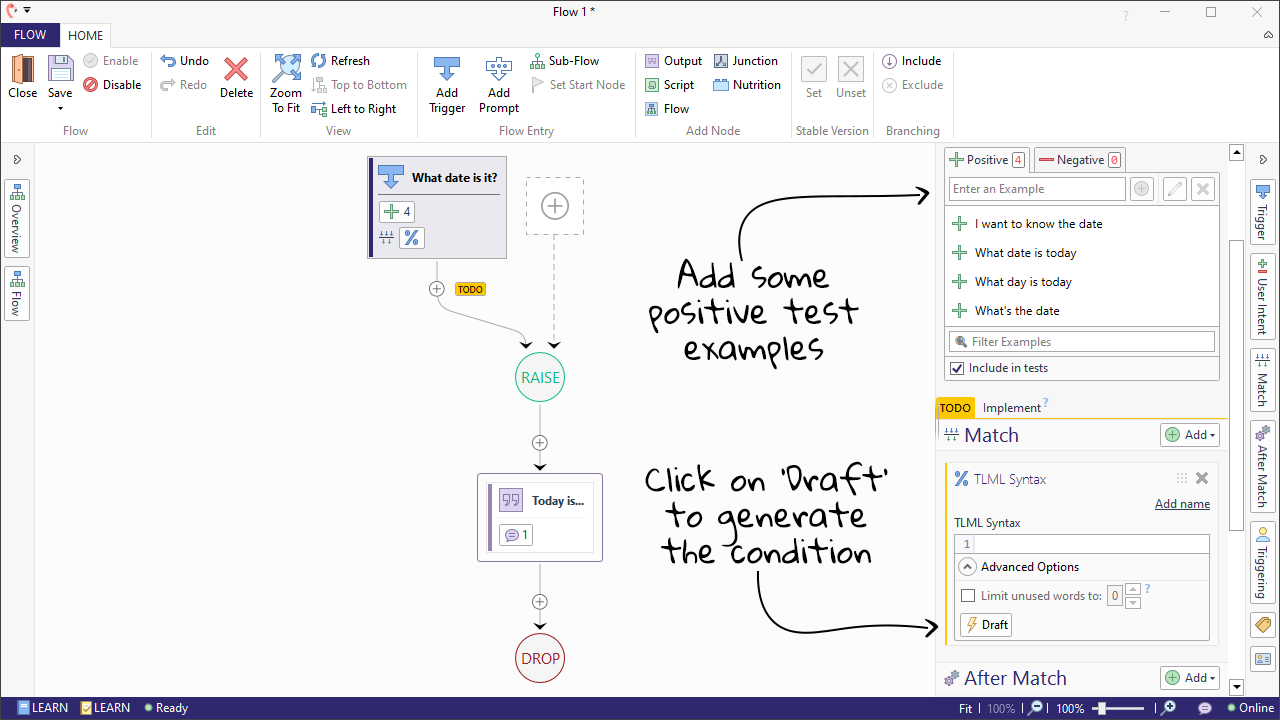
- See Conditions to read more about this topic.
Natural Language Processing
Teneo's powerful Natural Language Processing capabilities are key to the effectiveness of Teneo Linguistic Modeling Language (TLML). Teneo processes user input accurately and efficiently and annotates it with useful information, from Part-of-Speech (POS) tags to Named Entity Recognition (NER) tags. These tags can also be used inside conditions, allowing developers to check for the presence of certain POS or NER tags in a user's input.
If you want to see how an input is annotated, enter the input in Try Out and open the 'Advanced' window.. You will find all annotations in the Input section under 'Annotations'. Hovering over an annotation will display additional information that is stored in annotation variables.
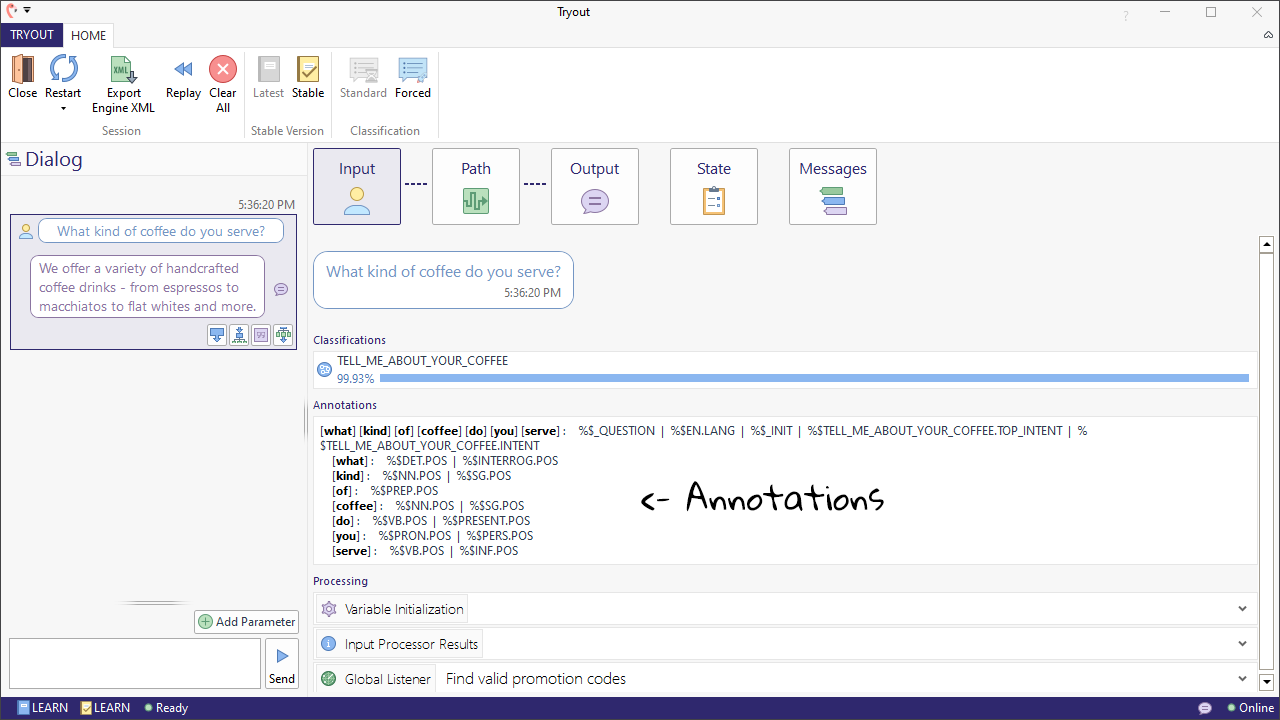
Part-of-Speech tags
The machine-learned Part-of-Speech tagger (or POS tagger) that comes with Teneo attaches one or more POS tags to each word in the input. POS taggers are available for Chinese, Danish, Dutch, English, French, German, Italian, Japanese, Korean, Spanish, Swedish, and Turkish. Here's a list of the English POS tags. Each language has their own list of relevant Part-of-speech tags. The entire list for each language Part-of-Speech tags can be found here.
| Condition | Description |
|---|---|
| %$3RDPERSON.POS | Verbs in third person |
| %$ADJ.POS | Adjectives |
| %$ADV.POS | Adverb |
| %$BRACKET.POS | Brackets {}()[] |
| %$CARDINAL.POS | Cardinal numbers |
| %$CC.POS | Coordinating conjunctions |
| %$COMPARATIVE.POS | Comparative adverbs and adjectives |
| %$DET.POS | Determiners |
| %$EX.POS | Existential 'there' |
| %$FOREIGN.POS | Foreign words |
| %$GERUND.POS | Gerund verbs |
| %$INF.POS | Verbs in infinite tense |
| %$INTERJ.POS | Interjections |
| %$INTERROG.POS | Interrogative (question) words, function words used to begin a wh- question, like what, who, when |
| %$LS.POS | List item markers |
| %$MODAL.POS | Modal verbs |
| %$NN.POS | Nouns |
| %$PARTICIPLE.POS | Verbs in past participle |
| %$PARTICLE.POS | Particles |
| %$PAST.POS | Verbs in past tense |
| %$PERS.POS | Personal pronouns |
| %$PL.POS | Nouns in plural |
| %$POSITIVE.POS | Positive adverbs and adjectives |
| %$POSS.POS | Nouns and pronouns expressing possession |
| %$PREDET.POS | Predeterminers |
| %$PREP.POS | Prepositions |
| %$PRESENT.POS | Verbs in the present tense |
| %$PRON.POS | Pronouns |
| %$PROPER.POS | Proper nouns |
| %$PUNCT.POS | Punctuations such as .,:!" |
| %$SG.POS | Singular nouns |
| %$SUPERLATIVE.POS | Superlatives |
| %$SYM.POS | Symbols |
| %$VB.POS | Verbs |
Named Entities
Teneo comes with machine learned Named Entity Recognizers (NER's) for English, French, German, Italian, Japanese, Spanish, Swedish, and Turkish. Here's a list of examples:
| Condition | Description | Examples |
|---|---|---|
| %$ADDRESS.NER | Street names and street numbers when applicable | I live on 2967 Washington st.What time does the office on Birch avenue open?I recently moved to 23 Main street. |
| %$CULTURAL_GROUP.NER | Nationalities, ethnic groups, religious groups, etc. | Do you accept students from German universities?I need to order special food on the flight, I am Muslim.Mum is cooking great Arabic food. |
| %$DATE.NER | Full dates (year, month, day) | I was born on April 7th, 1991.The ticket was issued 23 Jan 2017.I have been a customer since 14-03-2015. |
| %$EMAIL.NER | Email addresses | E-mail it to john.doe@artificial- solutions.comMy email is tester at yahoo dot com |
| %$EVENT.NER | Events, national holidays, treaties, awards/prices, etc. | Who won the Oscar's last night?Where are you celebrating Christmas this year?The treaty of Versailles was signed in 1919. |
| %$FACILITY.NER | Buildings, airports, train stations, public transport lines, hospitals, etc. | I want to fly from Newark to LAX.Have you ever visited the Empire state building?What year was the Brooklyn Bridge built? |
| %$FICTIONAL_FIGURE.NER | Fictional figures, cartoons, etc. | Who do you think you are, Superman?He was wearing a black coat, a bit like Batman’s.I don't believe in Santa Claus. |
| %$GEOGRAPHY.NER | Non-political geographical entities: mountains, bodies of water, planets, moons, suns, etc. | How many rings does Saturn have in total?Who was the first one to climb Mount Everest?How big is the Sahara Desert? |
| %$IP.NER | IP addresses | Connect to 10.1.2.148 |
| %$KNOWN_FIGURE.NER | Known, public (non-fictional) figures | Barack Obama was the President of the United States for 8 years.I am a big fan of Meryl Streep.Play a song from Justin Bieber. |
| %$KNOWN_GROUP.NER | Known groups and bands | Play a nice song by The Beatles.I liked the latest Coldplay album.Another song from Metallica please. |
| %$LANGUAGE.NER | Languages | Do you have this document in Swedish?Translate ‘hello’ to Hindi.I speak thee languages: Polish, English and Urdu. |
| %$LOCATION.NER | Geopolitical locations (humans made the borders), including: continents, countries, states, counties, cities, neighborhoods, etc. | I was born in California.I want to fly from Paris to London.What time does the ferry to Staten Island depart? |
| %$MED_CHEM.NER | Medical/chemicals: chemical substances, named diseases, and drugs | Is there a vaccine for Malaria?Who really discovered the Penicillin? Find me information about Iodine. |
| %$MISC.NER | Miscellaneous: named entities that fit none of the other categories | The Tyrannosaurus Rex could be over 6 meters high.What happened to Obamacare?What is the Erasmus programme? |
| %$ORGANIZATION.NER | Organizations: companies or a division of a company, universities, schools, embassies, religious organizations, political parties, etc. | I work at Apple.What is the e-mail address toArtificial-Solutions?I studied at Harvard University. |
| %$PERSON.NER | Names of persons, including titles and surnames if present | My name is Mrs Johnsson.The ticket is booked in the nameJoanne Stevens.Send a text to John please. |
| %$PRODUCT.NER | Product or brand names or organization names used as products in the context | I drive a BMW.How much is the new iPhone X?Can you open Facebook and make a post for me? |
| %$SPORTS.NER | Sports teams, sports organizations, sporting events | Miami Dolphins is a good team!I want to watch the winter Olympics.Who won the FIFA world cup? |
| %$UNIQUE_IDENTIFIER.NER | Unique identifiers: product numbers, phone numbers, user names, member numbers, etc. | My phone number is 123-44 43 33.I have a bonus card with number ebb123523111.When will 103-121-111 be in stock again? |
| %$UNIT.NER | Established units with value, including but not limited to: duration, age, temperature, percentage, information (bits) weight, volume, speed, length, currency | My phone has 64 GB.This flight has cost me almost $600.We have more than 750 miles to go. |
| %$URL.NER | URLs (also partial / truncated URLs) | Open google.comGo to page www.test.comTake me to cnn dot com |
| %$WORK_OF_ART.NER | Works of art: songs, albums, movies, books, video games, etc. | Do you read the Bible?Play Dimond’s with Rihanna.Download Frankenstein movie. |
| %$ZIP_CODE.NER | Zip codes | My zip is V0G 1Y0.My address is 24 Main street 23212 New York. |
- See Annotations to read more around this topic.
Scripting
Teneo Linguistic Modeling Language (TLML) is a powerful tool when personalizing conversations. With minimal effort, it is possible to create a personalized experience with a user based on the interactions they have. This in return gives a better bot-customer relation, where users can feel more confident about the bot.
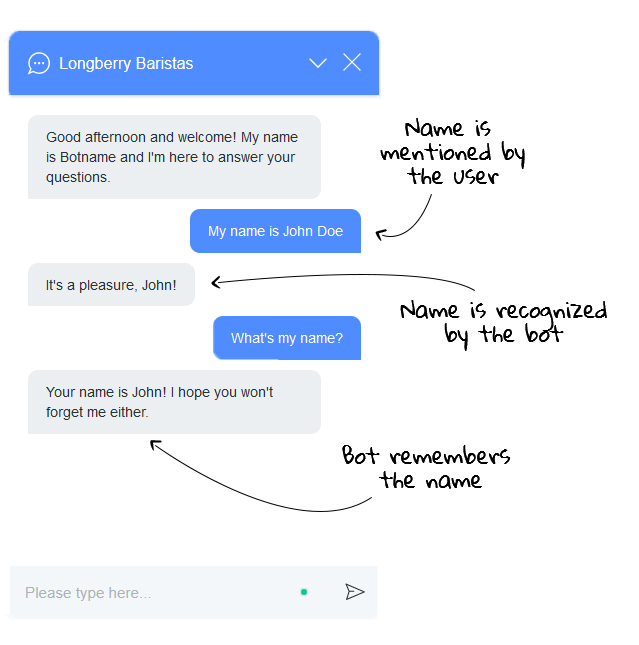
One way of personalizing conversations is through scripting. Scripting makes it easy to retrieve all required information from user input and to store that information in variables. The easiest way to do this is using the _USED_WORDS command, which picks out the relevant parts of the input. In the following example,_USED_WORDS is used in two conditions to store the user's name in the variable userNameForOrder. In one condition, the user's name has been recognized and annotated with a NER tag, and in the other, the name has not been annotated; in both cases, _USED_WORDS makes it simple to store the required information:

This is also demonstrated within this conversation that takes place in one of our Channel connectors, Teneo Web Chat.
- See Scripting to read more about this topic.
When should I use Teneo Linguistic Modelling Language?
Teneo Linguistic Modeling Language (TLML) is useful in every aspect of your solution, no matter how complex or simple the use case. As the concept itself is not dependant on training data, the user is able to, in their own world, build and create the rules for any single use-case — something that is not achievable when only using machine-learning.
An example of a use case that would benefit from TLML is one in which you need to combine class-based triggers with additional rules. For example, the inputs "I want to cancel my trip" and "You canceled my trip" are very similar in terms of words used and structure, but very different in terms of meaning. This is a clear example of a limitation of approaches relying on machine learning only; strictly machine-learned bots would not be able to consistently and accurately parse such inputs. With the TLML approach, on the other hand, Teneo can handle inputs like these and understand the differences between them.
Another example of a use case that benefits from TLML is the distinction between singular and plural word forms. A machine-learning-based model would not differentiate between the words 'ticket' and 'tickets' in user input. Using TLML, however, makes it simple to distinguish between the two. It is a great addition and works perfect in any complex case, no matter the language.
Linguistic Modelling Language works exceptionally well when you are working with morphologically complex languages, such as agglutinative languages, and/or when you are creating triggers for very specific use cases. As agglutinative languages make frequent use of affixes, it is very hard for a machine-learned trigger to differienciate two letters compared to two words in a non-agglutinative language.
Let's consider English and Turkish, with the example sentence "I like you". When adding a negation to this sentence it becomes, "I don't like you". In order to achieve this in English, we only needed to add a single word: "don't". For a machine-learned based trigger, this is an easily recognizable change and would therefore affect the triggering of this particular sentence.
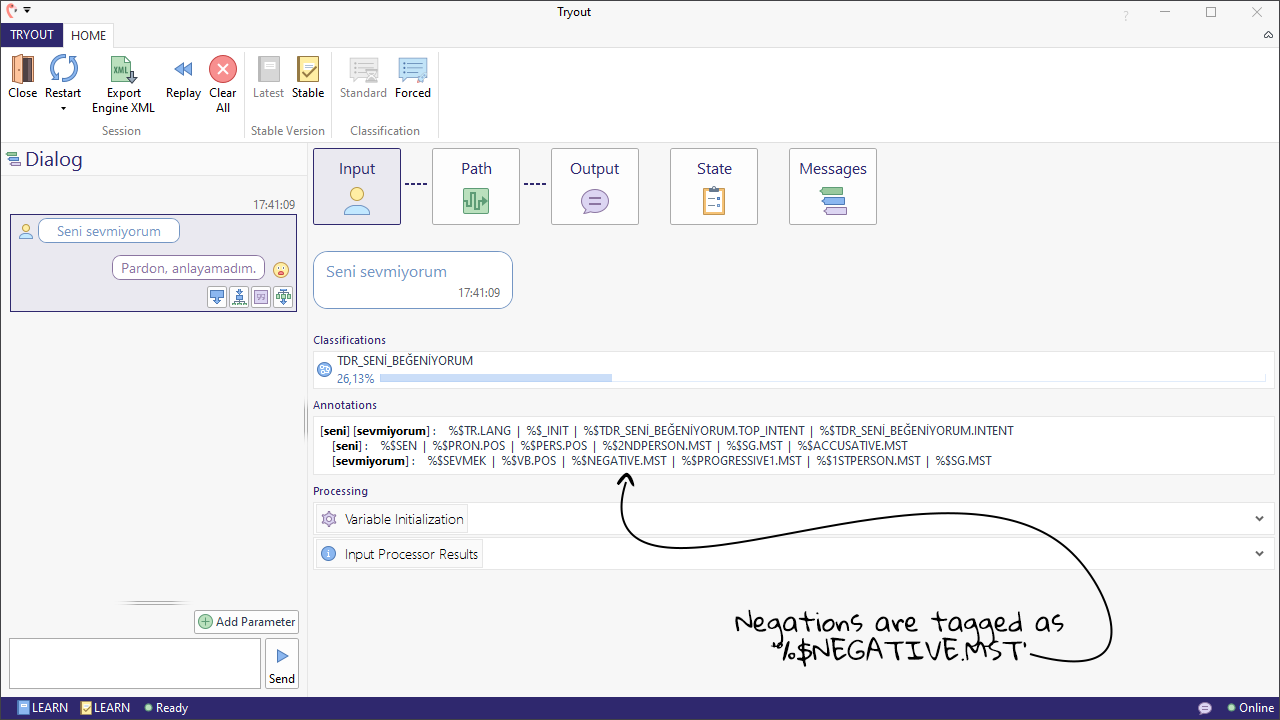
On a morphologically complex language like Turkish, however, "I like you" is "Seni seviyorum", which is two words instead of three. When adding a negation, this sentence becomes "Seni sevmiyorum", where the difference is a single letter. This is not only extremely hard for a machine-learned based trigger to differentiate, but could also be very easily misspelled by a user. Not being able to target these small changes can have a huge impact of the overall performance in your solution and is where TLML is especially powerful.
| English | Turkish |
|---|---|
| I like you | Seni seviyorum |
| I don't like you | Seni sevmiyorum |
In addition to this, Teneo also annotates negation words with a special %$NEGATIVE.MST tag that can be useful when building solutions in these morphologically complex languages.
- See Languages to read what languages are supported in Teneo.
Language objects re-use Teneo Linguistic Modeling Language
Language objects are one of the features in Teneo that work very well together with TLML. Language objects are building blocks for language conditions. They capture words, synonyms, or various ways of expressing the same (partial) intent. They make it possible to efficiently write and re-use conditions. In Teneo, we have naming conventions for Language objects to reflect their intended usage. More on this can be read in Language Objects.
Types of language objects
| Suffix | Type | Example Name | Example Condition | Generate NLU* |
|---|---|---|---|---|
| LEX | Lexical entry: the smallest building block from which more complex language objects are built. Covers different inflections of a word, but also spelling and regional variations. | DOG.NN.LEX | dog / dog's / dogs / dogs' | yes |
| MIX | Mixed entry: groups LEX language objects that share the same root. | HAPPY.ADJV.MIX | %HAPPY.ADJ.LEX / %HAPPILY.ADV.LEX | yes |
| MUL | Multi-word unit: forms the multi-word correspondence to the LEX language objects in that they capture the dictionary-level entries of multi-word units that are meant to be used as building blocks in higher level language objects. | GIVE_UP.VB.MUL | %GIVE.VB.LEX + %UP.FW.LEX | yes |
| SYN | Synonym set: groups LEX/MUL language objects with similar meaning. | DOG.NN.SYN | %DOG.NN.LEX / %HOUND.NN.LEX / %MUTT.NN.LEX / %POOCH.NN.LEX / (...) | yes |
| ENTITY | Entity: entity-related concepts, such as colors or country names. Entities typically have columns with variables attached to them. Each entity in CURRENCY.ENTITY, for example, has a currency code. | CURRENCY.ENTITY | See here for an example Entity | yes |
| LIST | List: lists-related concepts, such as colors or country names. A list often contains other lists. | COLOR_SHADES.LIST | %COLOR_SHADES_BLUE.LIST / %COLOR_SHADES_BROWN.LIST / %COLOR_SHADES_GRAY.LIST / (...) | no |
| PHR | Phrases: groups various ways of expressing the same phrase or partial intent. | IS_BROKEN.PHR | ((%BE.VB?PRESENT.LEX / %SEEM.VB.SYN)>> %BROKEN.ADJV.SYN ) / (...) | yes |
| THEME | Theme: groups words with a common theme. | WEATHER.THEME | (%RAIN.NNVB.SYN / %SNOW.NNVB.SYN / %SUNNY.ADJ.LEX / %RAINDROP.NN.LEX / (...)) | no |
| PROJ | Project: these language objects act as place-holders in the language resources. Should be customized to fit your project. | COMPANY_NAME.NN.PROJ | ((%YOUR.FW.LEX / %THE.FW.LEX ) >> %COMPANY.NN.SYN) / %ARTIFICIAL_SOLUTIONS.NN.SYN | yes |
| REC | Miscellaneous: contains condition that does not fit under any other category. | HOW.REC | %HOW.FW.LEX / %HOWS.FW.LEX / %HOWRE.FW.LEX / %HOWD.FW.LEX / (...) | no |
| SCRIPT | Script: language object: contains scripts, e.g. to count words or sentences. | WD_LT4.SCRIPT | {_.getSentenceWords().length<4} | no |
| ANNOT | Annotation: language object: contains annotation labels, and may be used instead of the labels themselves. This is deprecated, please use .ENTITY instead. | POS_NOUN.ANNOT | %$NN.POS | no |
- See Language Objects to read more about this topic.
Libraries re-use Language Objects
Teneo comes with a large number of supported languages. All languages that are supported by Teneo can be processed by the Teneo Engine, meaning user input can be split into tokens and sentences. When additional resources are required, we can create our own project-specific library. Libraries are powerful tools, as they not only allow us to create and use the resources we need in an efficient manner, but also allow us to re-use language objects across multiple bots. Language objects created in your solution can later be used to build a library. This library can later be re-used, saving the developer a lot of time and making the solution perform much better across different languages.

- See Libraries to read more about this topic.
Vocabulary
Many of the words covered in the libraries are structured in a hierarchy with more general language objects at the left and more specific entities at the right. This allows you to use the degree of granularity you need for your current bot. To give an example, sometimes it might be sufficient for you to know that the user is talking about an alcoholic drink, while in other cases it may be crucial to know the exact type of beer the user wants to order. Below, we show a simplified part of the hierarchical structure used for drink-related vocabulary, %DRINKS.LIST.
- See Vocabulary to read more about this topic.
More information
More information can be found in our reference documentation here.