Teneo NLU Ontology and Semantic Network
Introduction
The Teneo NLU Ontology and Semantic Network is Artificial Solutions’ proprietary Lexical Resources containing off-the-shelf building blocks to be used for building Natural Language Interaction (NLI) solutions in Teneo Studio; they are pre-build and cover the most common language conditions and phrases that Teneo applications most likely will need; they are the base upon which general, domain, and client / project specific Language Objects, Entities, and Flows can be built within the context of each project and are structured to facilitate the understanding of a specific language, such as English, Swedish, or Chinese.
The Teneo NLU Ontology and Semantic Network comes as a component of the Teneo Platform in the form of Lexical Resources, and once assigned to a solution can be used within the TLML syntaxes seamlessly, with no difference to Language Objects and Entities defined by the developer.
Maturity levels
Thinking of the Teneo Platform as a learner of foreign languages that is more proficient in some languages than others, just as a foreign language learner, the Teneo Platform is continually evolving and expanding its language knowledge by learning new languages and by improving in others. Therefore, the different Lexical Resources in the Teneo NLU Ontology and Semantic Network have different maturity levels as seen in the table further below.
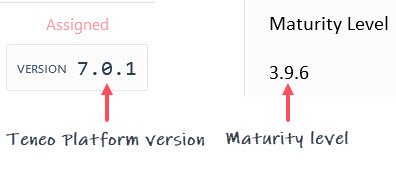
The version number of a Teneo Lexical Resource is composed of two parts:
- the Lexical Resources are released from and are compatible with the version of the Teneo Platform that the Resource was developed on; the first part of the version number indicates the Platform release version, e.g. 7.0, 7.2.1, 7.0.1 etc.
- the second part of the number is a build number of the Lexical Resource and gives information regarding the maturity level, e.g. 3.5.17, 3.9.0, etc.

The below table displays the current maturity levels of the Teneo NLU Ontology and Semantic Network's Lexical Resources.
| Language | Maturity level (Teneo 7.4) |
|---|---|
| Bulgarian | 1.0.9 |
| Chinese (Mandarin) | 3.5.12 |
| Czech | 2.0.1 |
| Danish | 2.5.12 |
| Dutch | 1.6.2 |
| English | 3.10.4 |
| French | 1.8.12 |
| German | 3.9.12 |
| Indonesian | 0.3.13 |
| Italian | 2.6.11 |
| Japanese | 2.8.12 |
| Malay | 0.2.13 |
| Norwegian (Nynorsk / Bokmål) | 1.8.12 |
| Portuguese | 2.4.12 |
| Russian | 0.9.19 |
| Spanish | 1.9.12 |
| Swedish | 2.10.4 |
| Turkish | 1.0.17 |
Structure overview
The Teneo NLU Ontology and Semantic Networks are structured hierarchically with lexical entries at the lower and complex Language Objects at the higher levels of the structure.
The underlying principle of this hierarchical arrangement is that the higher level of objects reference objects from the lower (linguistically less complex) levels, thus benefitting from any improvements that may be made on the lower levels during maintenance, but also increasing the overall consistency of the Language Object base and producing a leaner, more coherent structure overall.
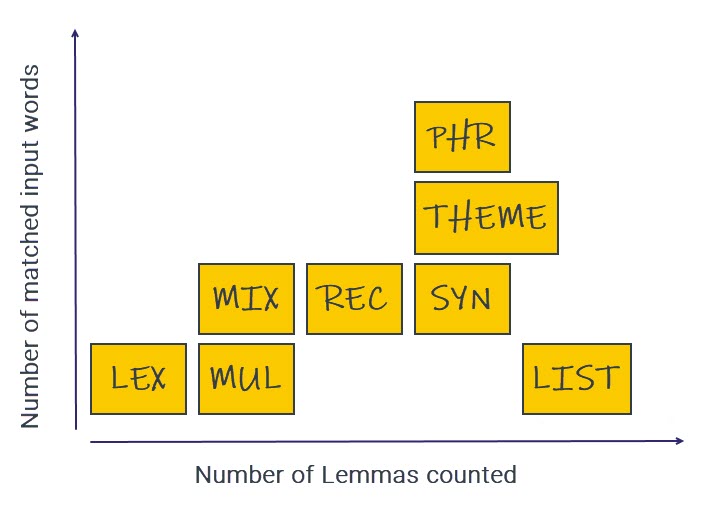
The following graph positions the Language Object types presently in use and categorizes them based on the number of lemmas they may contain as well as based on the number of words in an input sentence that each type typically is intended to capture.

Language Objects and Entities
An Entity is a container, typically, for list-like syntax while a Language Object is a container for any TLML syntax; both can be re-used in other Language Objects, Entities, and in TLML syntaxes throughout a solution in Teneo Studio.
Language Object naming conventions
The names of the Language Objects in the Teneo NLU Ontology and Semantic Network follow strict naming conventions and are composed of a sequence of the following elements:
- A mandatory kernel name (HAPPY, RUN, TELEPHONE)
- An optional suffix indicating part-of-speech added to .LEX (most), .MUL or .SYN:
- VB (verb)
- NN (noun)
- ADJ (adjective)
- ADV (adverb)
- FW (function word, preposition, particle, conjunction, non-inflected adverb, pronoun, etc.)
- ADJV (adjective and adverb), NNVB (noun and verb) On the SYN and MIX levels, the suffix can also be a combination of two indicators of part-or-speech
- An optional constraint operator expression
- GO.VB?PAST.LEX
- HAPPY.ADJ?COMP.SYN
- A mandatory Language Object type suffix (LEX, MUL, MIX, SYN, PHR, PROJ, THEME, etc.)
An example of a Language Object name containing all four of these elements could be:
tlml
1GO.VB?PAST.LEX
2In the NLU Ontology and Semantic Network, the kernel element in a Language Object should be in the local language, using local letters, whereas the suffixes are the same for all languages. One can think of them as "variable types" in programming language ("sting", "array", "Boolean", "integer", etc.) while kernels could be seen as "variable names".
On top of this, both Language Objects and Entities in the NLU Ontology and Semantic Network follow the general rules which applies to Language Object and Entities within the Teneo Platform where the objects' names must be upper-case letters and spaces or special characters are not allowed.
Language Object types
The below table provides an overview of the different types of Language Objects in the Teneo Lexical Resources; in the following sections please find more detailed information of each type.
| Suffix | Type | Description |
|---|---|---|
| LEX | Lexicon Language Objects | LEX Language Objects are the smallest elementary building block of a TLR from which more complex Language Object structures are built. They do not only cover different inflections of a word, but also spelling and regional variations. |
| MUL | Multi-word units | MUL Language Objects form the multi-word correspondence to the LEX Language Object in that they capture the dictionary-level entries of multi-word units that are meant to be used as building blocks in higher level Language Objects. |
| MIX | Mixed Language Objects | Mixed Language Objects group LEX Language Objects that represent lemmas deriving from the same lexical root, e.g. happy, happily and happiness. They typically contain entries with various part of speech. |
| SYN | Word-level Synonym Language Objects | SYN Language Objects are synonym objects at word-level. All the words grouped in a SYN should be interchangeable in the given context. |
| PHR | Phrase-level Language Objects | PHR Language Objects represent all possible ways of expressing a phrase or partial sentence, e.g. What is the price of X, I want to know or How long will it take for X to happen |
| THEME | Theme Language Objects | Theme Language Objects group words on the basis of a theme. The words generally have different meanings, but are associated to the common theme. One can think of theme Language Objects as keyword objects. |
| LIST | List Language Objects | LIST Language Objects contain lists of concepts, such as colors, car brands and countries. LIST Language Objects can be composed of other LIST Language Objects. |
| REC | Miscellaneous Language Objects | REC Language Objects are meant to store TLML syntaxes that do not fit under any other category but are still reused enough in different Linguistic Modeling Language syntaxes. They can be very wide, or rather specific, but do not have consistent structure. Both their scope and naming should be highly pragmatic. |
| PROJ | Project-specific Language Objects | Customizable company/project-specific Language Objects. A project can create a local copy of the object within their solution and make project-specific additions and adjustments. |
| SCRIPT | Language Objects containing Script | These are high-level Language Objects with scripts and functions, for example to count words or sentence or for table answers. |
| ANNOT | Annotation Language Objects | ANNOT Language Objects are meant as an abstraction layer for the annotations coming from the Input Processors. |
| SUPPORT | Support Language Objects | SUPPORT Language Objects are only meant to be used internally by the system (to support TLML syntaxes of other Language Objects). |
Lexicon Language Objects
tlml
1*.LEX
2The LEX Language Objects are the smallest, elementary building of a NLU Ontology and Semantic Network from which more complex Language Object structures are built. They not only cover different inflections of a word, but also spelling and regional variations when applicable.
One can think of LEX Language Objects as basic dictionary entries; a LEX corresponds to a lemma and captures a single full set of inflectional forms of a given word, irrespective of whether that set may have several different meaning or senses. Hence, there will only be one LEX created for a lemma and its set of inflectional forms, as illustrated in the following by the noun bark. Bark can mean both the sound that a dog makes and the surface layer of a tree trunk, but as long as both senses have the same lemma and are inflected in the same way, only one LEX Language Object is created for them.
Example
tlml
1BARK.NN.LEX
2bark/barks/bark's/barks'
3tlml
1BARK.VB.LEX
2bark/barks/barked/barking
3Multi-word units
tlml
1*.MUL
2The MUL Language Objects form the multi-word correspondence to the LEX Language Objects in that they capture the dictionary-level entries of multi-word units that are meant to be used as building blocks in higher level Language Objects.
Example
Phrasal verbs (verbs with a preposition) or multi-word nouns form typical MUL Language Objects in the English Lexical Resource
tlml
1GIVE_UP.VB.MUL
2(%GIVE.VB.LEX + %UP.VB.LEX)
3tlml
1GOOGLE_CHROME.NN.MUL
2(%GOOGLE.NN.LEX >> %CHROME.NN.LEX)
3Mixed Language Objects
tlml
1*.MIX
2Mixed Language Objects group LEX Language Objects that represent lemmas deriving from the same lexical root, e.g. happy, happily and happiness. They typically contain entries with various part of speech.
Example
tlml
1BULGARIA.MIX
2(%BULGARIA.NN.LEX / %BULGARIAN.NN.LEX / %BULGARIAN.ADJ.LEX)
3The MIX objects can have a suffix that specifies the different part of speech in the object, i.e. ADJV for adjective and adverb, or NNVB for noun and verb.
tlml
1HAPPY.ADJV.MIX
2(%HAPPY.ADJ.LEX / %HAPPILY.ADV.LEX)
3Word-level synonym Language Objects
tlml
1*.SYN
2Since natural language has various ways of expressing the same or very similar concepts, the Teneo NLU Ontology and Semantic Networks need structures to represent different types of synonyms. Synonyms can occur at word-level (i.e. different words denoting the same concept) and at phrase-level (different, linguistically more complex ways of expressing the same concept). Hence, synonym Language Objects are required at word-level and at phrase-level.
SYN Language Objects are synonyms at word-level; phrase-level Language Objects are marked as PHR (more information available in the next section).
A SYN typically groups LEX and/or MUL objects that represent words sharing the same - or a very similar - meaning. Words with similar meanings can be grouped in more than one way, bearing in mind different context and varying degrees of granularity. Words generally have more than one meaning or sense.
Note that SYNs are defined with respect to a certain sense of a word. The adjective sharp has at least two senses: the original one used for knives for instance, and a metaphorical one used for describing intelligent people: He is really sharp means the same as He is really intelligent, yet The knife is sharp cannot be replaced by The knife is intelligent. Therefore, these two senses should be represented by different SYN Language Objects.
Phrase-level Language Objects
tlml
1*.PHR
2The PHR Language Objects represent all possible ways of expressing a phrase or partial sentence, e.g. What is the price of..., I want to know..., How do I..., etc.
A linguistic phrase may be arbitrarily complex, and this is also the case with the PHR Language Objects; some capture noun units, while others capture several sentence constituents. As such, PHR Language Objects typically reference LEX, MUL, SYN and other PHRs.
Example
tlml
1HOW_DO_I_CHANGE.PHR
2(
3((%HOW_DO_I.PHR / %I_WOULD_LIKE_TO) >> %EXCHANGE.VB.SYN) / (...)
4)
5Theme Language Objects
tlml
1*.THEME
2The THEME Language Objects group words based on theme. The words generally have different meanings but are associated to the common theme. One can think of THEME Language Objects as keyword Language Objects.
Due to their supposedly wide scope, a THEME object is never selected for a TLML Syntax when generated by the NLU Generator's algorithms.
The TLML Syntaxes of THEME Language Objects are generally too wide for trigger TLML Syntax Matches or Language Object Matches in their own, but a useful application for a THEME is to use them for excluding a subject/theme from a Flow TLML Syntax.
Example
tlml
1WEATHER.THEME
2%RAIN.NNVB.SYN / %SNOW.NNVB.SYN / %SUNNY.ADJ.LEX / %RAINY.ADJ.LEX / (...)
3List Language Objects
tlml
1*.LIST
2LIST Language Objects contain lists of concepts, such as car brands, food and drinks, etc. LIST Language Object can be composed of other LIST Language Objects.
For easy retrieval and overview, related lists share the first part of their names:
tlml
1CITITES.LIST, CITIES_EUROPE.LIST, CITIES_ASIA.LIST, ...
2tlml
1COLORS.LIST, COLORS_BASIC.LIST, COLORS_SHADE.LIST, ...
2Due to their supposedly wide scope, a LIST Language Object is never selected for a TLML Syntax when generated by the NLU Generator's algorithms.
Project-specific Language Objects
tlml
1*.PROJ
2The PROJ are Language Objects that allow projects to include dynamic syntaxes. In the Teneo NLU Ontology and Semantic Networks these Language Objects are created with generic TLML Syntax, for example:
tlml
1COMPANY_NAME.NN.PROJ
2((%YOUR.FW.LEX / %THE.FW.LEX) >> %COMPANY.NN.SYN)
3It is up to each project to create a local copy of the object within their solution and make project specific additions and adjustments, e.g. adding the actual name of the company to the Language Object of the above example.
The local Language Object will always be selected, as Engine will override a Language object from any lexical resource with the local version of the same Language Object.
Miscellaneous Language Objects
tlml
1*.REC
2The REC Language Objects are meant to store TLML Syntax that do not fit under any other category but are still reused often enough in different trigger TLML Syntax Matches or listeners. They can be very wide, or rather specific, but do not have consistent structure. Both their scope and naming are highly pragmatic.
Script Language Objects
tlml
1*.SCRIPT
2The SCRIPT Language Objects are typically to control the non-linguistic part of a TLML syntax; some script objects for example count the words in a user-input while others are useful to find where in the user-input a specific word came.
Example
tlml
1WD_1.SCRIPT
2The above Language Object's TLML Syntax only matches user-inputs with one word.
tlml
1SNT_2.SCRIPT
2The above Language Object's TLML Syntax only matches user-inputs with two sentences.
tlml
1SENTENCE_START.SCRIPT
2The above Language Object's TLML Syntax only matches if a specific word comes first in the user-input.
Support Language Objects
tlml
1*.SUPPORT
2The SUPPORT Language Objects are only ever meant to be used internally by the system (to support TLML Syntax of other Language Objects); and as these SUPPORT Language Objects are not intended for use within solutions, they are not included as suggestions when using the auto-complete functionality or the Condition building assistant in the TLML Syntax editor. Users can, however, still find them with the search functionality.
Annotation Language Objects
tlml
1*.ANNOT
2The ANNOT Language Objects are meant as an abstraction layer for the annotations coming from the Input Processors. In addition, their name prefixes make them more easily discoverable when writing TLML syntaxes and using the auto-completion functionality. They sometimes make sense to use together with the Same Match (&=) - operator or Bigger Match (&>) - operator.
There are several classes of ANNOT Language Objects available in the NLU Ontology and Semantic Network, please see the following sections for more information.
Number ANNOT Language Object
All the Lexical Resources of the NLU Ontology and Semantic Network contain a NUMBER.ANNOT Language Object designed to capture Arabic numbers and the TLML syntax is the number annotation provided by the Basic Number Recognizer Input Processor.
| Number ANNOT Language Object | Annotation(s) used as syntax |
|---|---|
| NUMBER.ANNOT | NUMBER (Identifies Arabic numbers of the type 123 and 3.14) |
Language ANNOT Language Object
All the NLU Ontology and Semantic Networks contain a LANGUAGE.ANNOT Language Object which TLML syntax contains all the available annotations provided by the Language Detector Input Processor.
| Language ANNOT language object | Annotation(s) used as syntax |
|---|---|
LANGUAGE.ANNOT | AR.LANG (Arabic) / BG.LANG (Bulgarian) / BN.LANG (Bengali) / CA.LANG (Catalan) / CS.LANG (Czech) / DA.LANG (Danish) / DE.LANG (German) / EL.LANG (Greek) / EN.LANG (English) / EO.LANG (Esperanto) / ES.LANG (Spanish) / ET.LANG (Estonian) / EU.LANG (Basque) / FA.LANG (Persian) / FI.LANG (Finnish) / FR.LANG (French) / HE.LANG (Hebrew) / HI.LANG (Hindi) / HU.LANG (Hungarian) / ID_MS.LANG (Indonesian/Malay) / IT.LANG (Italian) / JA.LANG (Japanese) / KO.LANG (Korean) / LT.LANG (Lithuanian) / LV.LANG (Latvian) / MK.LANG (Macedonian) / NL.LANG (Dutch) / NO.LANG (Norwegian) / PL.LANG (Polish) / PT.LANG (Portuguese) / RO.LANG (Romanian) / RU.LANG (Russian) / SK.LANG (Slovak) / SL.LANG (Slovenian) / SR_HR.LANG (Serbian/Croatian/Bosnian) / SV.LANG (Swedish) / TA.LANG (Tamil) / TE.LANG (Telugu) / TH.LANG (Thai) / TL.LANG (Tagalog) / TR.LANG (Turkish) / R.LANG (Urdu) / VI.LANG (Vietnamese) / ZH.LANG (Chinese) |
Morphological ANNOT Language Objects
The Part-of-Speech (POS) Taggers and Morphological Analyzers are available in various languages as part of the Teneo NL Analyzers; for more information please visit the POS Tagger and Morphological Analyzer Input Processors or see the per language specific information.
For languages where the POS Tagger and Morphological Analyzer Input Processor is available, the Lexical Resources contain supporting Morphological ANNOT Language objects which are distinguished between POS Language Objects, which are meant to capture part of speech such as verb and noun, and MST Language Objects, which are meant to capture morpho-syntactic traits such as noun number and verb tense.
Named Entity ANNOT Language Objects
The Named Entity ANNOT Language Objects are designed to condition on Named Entity annotations; currently these objects are available for Japanese and Turkish; read more
The Named Entity ANNOT Language Objects conditioning on annotations generated by the Named Entity Recognizer (NER) Input Processor were converted into Entities in Teneo 6.2
See full list of converted objects
Learn more about Entities in the TLRs
Stopwords
The handling of stopwords, used by the NLU Generator among others, is handled in the Teneo NLU Ontology and Semantic Network for all languages.
The stopwords make up a set of Language Objects, making them more visible and configurable. Users can customize the NLU Generator's stopword lists per needs by creating local copies of the Language Objects STOPWORDS_INCLUDE.PROJ and STOPWORDS_EXCLUDE.PROJ in the solution and add words to include or to exclude from the stopwords lists respectively.
Entities
Several of the NLU Ontology and Semantic Networks come with a set of prebuilt Entities; these Entities make use of different techniques, like hand-crafted lists or machine learned NERs to extract an Entity from an input.
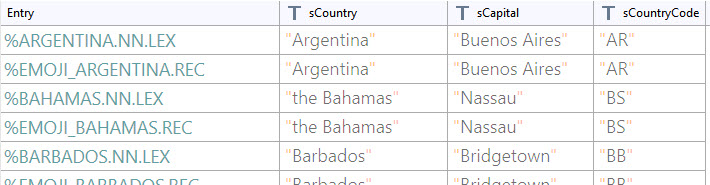
Entities make the matched Entity details available in one or more variables; for example, in the English Lexical Resource, the COUNTRY.ENTITY, not only provides the country name, but also the capital and country code as seen in the following image.
Read more about the machine learned NERs in the Named Entity Recognizer section or see the language specific information of the pre-built Entities.
NLU Variables
In the NLU Ontology and Semantic Networks, some of the Language Objects and Entities have NLU Variables; this is a variable which can hold a specific value.
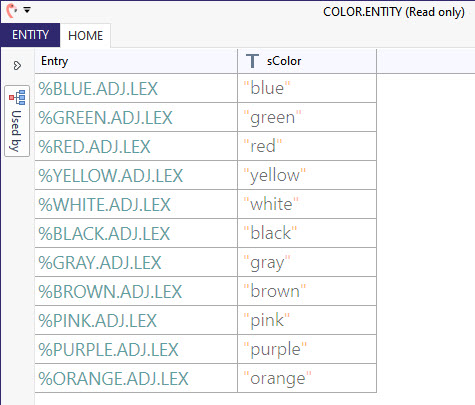
As an example, in the English Lexical Resource, the COUNTRY.ENTITY returns the variables sCountry, sCapital and sCountryCode, where all entries set a corresponding value, i.e. CANADA.NN.LEX sets the variable sCountry to Canada, the variable sCapital to Ottawa and the variable sCountryCode to CA.
Also in the English Lexical Resource, the COLOR.ENTITY returns the variable sColor, where all entries set the corresponding value, i.e. BLUE.ADJ.LEX sets the variable sColor to blue.